Nextdoor Notifications: How we use ML to keep neighbors informed

One of the top reasons neighbors tell us they come to Nextdoor is to stay informed. We help neighbors stay informed with relevant updates that are timely, local, and connected to people and places that matter to them.
Author: Karthik Jayasurya
A copy of this study was also shared on the Nextdoor Engineering Blog, which you can see here.
Introduction
At Nextdoor, we help neighbors, small businesses, large brands, and public agencies create trusted connections and exchange helpful information, goods, and services. One of the top reasons neighbors tell us they come to Nextdoor is to stay informed. We help neighbors stay informed with relevant updates that are timely, local, and connected to people and places that matter to them. Nextdoor provides these updates through what we refer to going forward as ‘notifications’, which includes email, push, and in-product notifications. We provide neighbors control to these notifications and they have the capability to dial up/down these channels based on the frequency they desire at any time. These notifications help neighbors stay informed on what’s most important in their neighborhood and actively contribute to their communities.
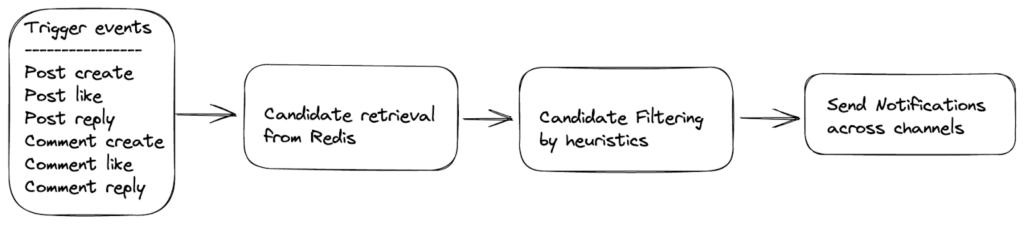
Some of our most valuable and voluminous notifications are those that notify neighbors of “new” or “trending” posts that are available in their vicinity. These two types of notifications are sent in real-time to chosen audiences in order to best provide relevant updates in a timely manner. Specifically:
- New Post Notifications: Sent immediately after the post is created.
- Trending Post Notifications: Sent as the post generates conversation and becomes more popular/trending over time.
In this blog post, we will share the underlying system for how we send the right notification to the right neighbor at the right volume using machine learning. The focus of this article is slightly more on the decision-making system and less on infrastructure details. The latter would be better suited in another future blog. We will also discuss a few practical issues and learnings to guide the future design choices.
How did the legacy system make decisions?
Before we transitioned to machine learning, we used a simple heuristic method to figure out the best audience to send new and trending notifications. The heuristic relied on basic engagement criteria of the post. As the post got more engagement, incrementally more neighbors would be notified of the conversation. We also used some guardrails to ensure that neighbors were not over-notified. We employed notification budgets and “pacing” logic to ensure that notifications were never sent in a way that provided an unintentionally bad experience.
Although the heuristic system served us well for a considerable amount of time, one big drawback of this approach is that the recipient audience is a random sample of eligible neighbors for the notification. Many of our neighbors expect us to be able to more deeply understand why a particular notification might be relevant to them. Machine learning allows us to better leverage the interests neighbors have and better understand what posts are about. Therefore, the motivation for a machine learning based design is to improve the quality of sent notifications and increase the value to our neighbors.
ML models for ranking audience
The machine learning based relevance model predicts how interesting and engaging a new or trending post notification might be specifically to a neighbor. In order to predict the relevance of a particular notification, the model considers the following features:
- Content-based features such as posting time, the subject and body text of post, post topic, and aggregated real-time interaction metrics (e.g. clicks, opens, taps).
- Recipient-based features such as a neighbor’s last time visiting Nextdoor, the frequency at which they visit, and how long the neighbor has been on Nextdoor.
- Author-based features such as geographical proximity to the recipient and the similarity or “dot product” between the embeddings of the author and the recipient.
After iterating on a few classical algorithms, we found that the XGBoost model provided the best performance for predicting email clicks and push taps. The tree based models can handle both categorical and continuous features out of the box and are generally very predictive with minimal feature pre-processing.
More complex attributes like text are converted to embedding representations using a separate word embedding model that is trained on the Nextdoor ecosystem. In order to pipe them into the model, we first create offline representations of author and recipient embeddings and use the dot products between post, author and recipient embeddings as similarity features into the XGBoost model.
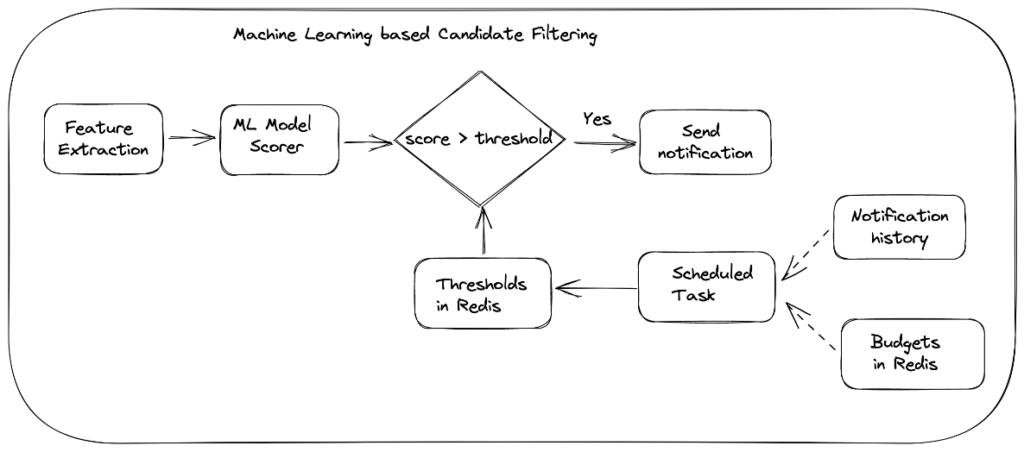
The model’s score measures the propensity of click or tap and higher scores would mean that notifications for that post are of better quality and relevance to the particular neighbor. The model is trained on both email and push channels together, so as a result, we encode the channel as a feature in the model and evaluate relevance scores separately for each channel. This ensures all the common features are leveraged into a single model optimizing both the click and tap rates together, instead of learning separate channel specific models.
Volume control with notification budgets
While the ML model scores notifications based on relevance, in practice, we are interested in knowing the best notifications to send within a certain notification budget. Simply sending more notifications can drastically boost overall engagement metrics in the short term. However, this strategy will create a poor experience for neighbors in the long term, especially when there is high liquidity of good quality candidate notifications. Sending too many notifications will cause even the most interested neighbors to unsubscribe from email or push notifications or uninstall the app and degrade the neighbor’s trust in Nextdoor. As a result, neighbors will likely miss important updates happening in their neighborhoods.
To address this, each neighbor is assigned a weekly notification budget to represent the maximum number of notifications we can send to that neighbor per notification channel. We deployed a separate model that refreshes these budgets periodically based on a score that is aggregated from both positive signals like clicks/opens/taps and negative signals such as number of unsubscriptions. Full details of the budgets model are out of scope for this blog post, but the model computes and writes these budgets into a redis store taking into account recent neighbor engagement and unsubscription patterns. Once the neighbor budgets are determined for both email and push channels, the goal is to send the most relevant notifications across channels while respecting the channel-specific weekly budgets for every neighbor.
Threshold estimation using model scores
Hypothetically, for a given neighbor, if we knew all the future notifications that would ever be considered during that week beforehand, we could just score all of them using a relevancy model and only send the top scored N notifications whenever they are considered during that week, N being the neighbor’s weekly budget.
In reality, we can neither predict the quality of future posts nor know exactly how many candidate notifications each neighbor could be considered for. Moreover, the decision to send or not to send needs to be made in real-time for a given post to notify neighbors in a timely manner. To do this, we estimate personalized “thresholds” that represent cutoffs on model scores, and only send notifications for posts whose scores exceed the threshold while maximizing the threshold itself.
To estimate these personalized thresholds, we started with the approach of using historical data to estimate a cutoff that sends the most relevant content to neighbors while limiting the total volume of notifications. To do this, we first had to aggregate the scores for every notification candidate over a previous weekly time span. Then, we made a simple assumption that if we set the threshold as the Nth highest score (where N is the neighbor’s budget), it would be a good estimate for the following week. We had deployed this in our first version by efficiently implementing it using the Q-digest data structure [1, 2] and it resulted in significant positive impact to our top line engagement metrics.
Even though we had a great neighbor impact with this method, there were a few challenges.
- First, the threshold estimates are sensitive to extreme scores because the tails of the distribution are noisy and have high variance.
- Second, there is a hard-to-correct bias associated with the fact that one post can be scored many times as it generates conversation, but it is only sent at most one time. More generally, the score distribution doesn’t capture business logic that may or may not allow a candidate to be sent.
- Third, and more practically, anytime there is an outage or issue that affects overall notifications sent, the gap in score history reverberates in the system for a long time, resulting in an inability to recover quickly.
PID system based thresholds
To tackle these problems, we decided to utilize a method that did not rely on this type of forecasting to estimate thresholds. Our learnings showed we needed to dynamically adjust our thresholds to optimally hit the notification budget for each neighbor. We decided to utilize a classical method in control theory, PID (proportional-integral-derivative) controllers [3].
The closed-feedback loop system adjusts the threshold to drive the “error signal” to zero as quickly as possible. In this case, the “error signal” was the deviation between the actual number and budgeted sent notifications. If we send too many notifications, we increase the threshold and make it harder to send notifications and vice versa. The PID system has the advantage of converging to unbiased thresholds always no matter how the business logic or rules change as it only depends on the history of sent notifications. As a result, we’ve found that we can better meet neighbors’ budgets more consistently with the PID system compared to the forecasting-based approach.
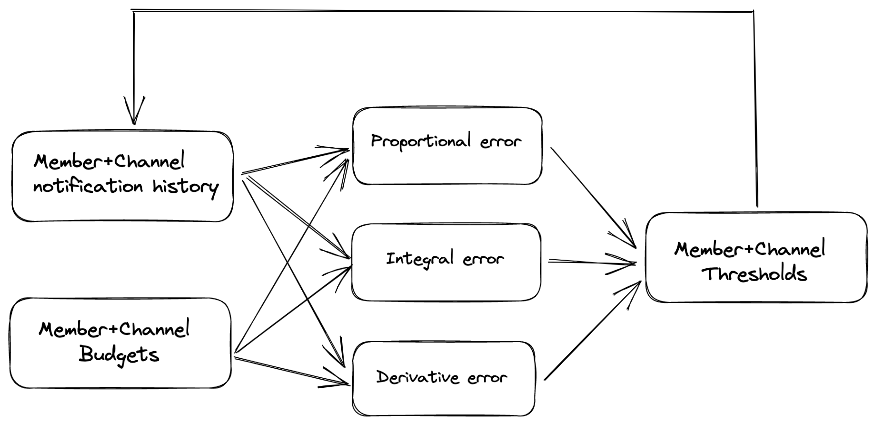
Once a day, a scheduled task is triggered to read the seven-day history of sent notifications and the latest budgets from redis for all neighbors and channels, where proportional, integral, and cumulative errors are computed and used to update the personalized thresholds on redis accordingly. It’s important to note that the target that the PID controller uses as the budget is actually a “soft budget” that is lower than the intended number of notifications calculated. This is so the PID controller can have access to both positive and negative “error signals” and adjust thresholds in both directions to meet our objective.
Impact on neighbor experience
We have run a set of AB tests to measure the real impact of neighbors receiving notifications through this approach. For the same notification volume, the ML based design led to a significant improvement in providing value to neighbors with up to 40% increase in click and 23% in tap rates across all operating countries compared to the legacy system. Overall, this resulted in a significant increase of 8% in daily active neighbors on the platform. Since its beginning, we have iterated on this design a few times with newer features and fresher datasets to improve the neighbor experience metrics every time.
In addition, the decision system also distributed more notifications to dormant and less active neighbors compared to highly active ones. This is a desirable volume skew in that the notifications provide more utility to dormant and inactive neighbors in helping them stay informed, while highly active neighbors derive most value from visiting Nextdoor organically. As a consequence, our active neighbor segments have lower unsubscribe rates, and our less active neighbors derive more value from Nextdoor by seeing the most important updates in their neighborhood.
Challenges with real-time design and thresholds
Although PID based thresholds represented an improvement over the previous forecasting method, tuning the PID parameters to be highly responsive is difficult. Even when tuned to respond quickly in a closed feedback system, a large set point change in notification budgets can cause damping oscillations to thresholds. This undesirable behavior can result in a bumpy notification delivery experience for neighbors. In addition, in a real-time setting, we have learned that inevitable outages to upstream data pipelines can potentially skew model features and model scores, which can lead to unpredictable notification volume. At the scale at which Nextdoor notifies its neighbors, an inconsistent experience for even a few minutes can negatively affect the top line neighbor experience metrics.
Current state and next steps
The current notification system has served us well over a year, delivering tremendous value to our neighbors globally while laying the groundwork for using machine learning to make notifications more relevant to neighbors. The real-time notification system has been very useful at sending notifications in a timely manner so neighbors can be informed about their communities through the right notifications at the right time and place. We have also learned that such a real-time system is more complex to maintain and make optimizations to consistently provide good neighbor experience challenging.
As we iterate our design, we are moving towards building a scheduled notification system. In this design, notifications are scheduled to be sent during pre-determined delivery times based on the neighbor’s most likely time to engage with Nextdoor. Such a system is more robust to impact from external events and has better control of notification delivery. We can also better “rank” notification candidates together for higher quality, while making sure that new and trending notifications are delivered in a timely manner. Ideally, we will build towards a system where both real-time and scheduled notifications can co-exist and share responsibility for sending different kinds of notifications by reasoning about the urgency of the content.
Conclusion and Acknowledgements
Building a ML notification system was challenging, deeply rewarding, and would not have been possible without a close collaboration between the Notifications ML team (Cathleen Li, Waleed Malik, Amit Lakhani) and Notifications Infrastructure team. The notifications teams are constantly striving to improve the value that notifications provide neighbors and help them connect with their community. We are constantly experimenting and learning quickly while making sure the infrastructure and tooling to support these notifications are able to provide a reliable and scalable solution as we grow.
Let us know if you have any questions or comments about Nextdoor’s Machine Learning efforts. And if you’re interested in solving challenging problems like this, come join us! We are hiring Machine Learning engineers. Visit our careers page to learn more!
References
[1] Medians and Beyond: New Aggregation Techniques for Sensor Networks
[2] Computing Extremely Accurate Quantiles Using t-Digests